本文更新于 2026-04-02
MySQL 索引概述 (Index)
索引是帮助 MySQL 高效获取数据 的 数据结构 (有序)。(⭐⭐⭐)
- 在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
索引的优缺点
| 特性 | 优点 | 缺点 |
|---|---|---|
| 查询效率 | 提高数据检索的效率,降低数据库的 IO 成本。 | 索引列也是要占用空间的。 |
| 排序效率 | 通过索引列对数据进行排序,降低 CPU 的消耗。 | 索引大大提高了查询效率,但降低了更新表的速度(如 INSERT、UPDATE、DELETE)。 |
索引的本质:数据结构
假设有一张包含数百万条记录的表,如果没有索引,数据库必须进行全表扫描 (Full Table Scan),即从第一行开始逐行比对,效率极低。
- 无索引:$O(n)$ 的时间复杂度。
- 有索引:通过 B+Tree 等结构,将复杂度降低至 $O(\log n)$。
索引结构
- 在存储引擎层实现,不同的存储引擎有着不同的索引结构
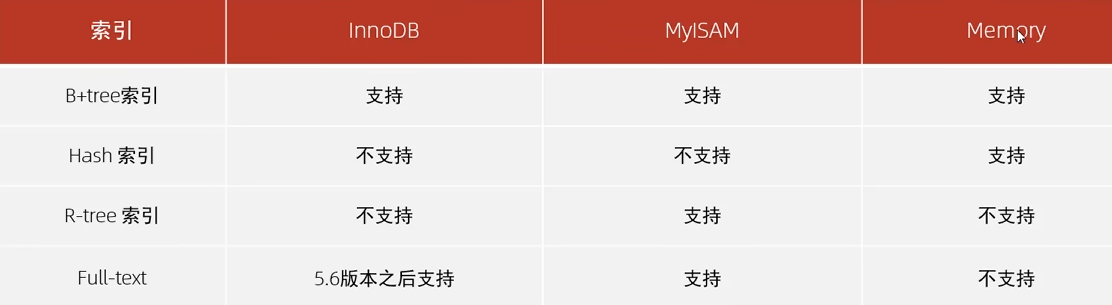
| 索引结构 | 描述 |
|---|---|
| B+Tree 索引 | 最常见的索引类型,大部分引擎都支持。 |
| Hash 索引 | 底层采用哈希表实现,只有 Memory 引擎支持,不支持范围查询。 |
| R-tree 索引 | 空间索引,主要用于地理信息数据类型(MyISAM 支持)。 |
| Full-text 索引 | 全文索引,通过建立倒排索引快速匹配文本中的关键词。类似于:Lucence,Solr,ES |
注意:InnoDB 具有自适应哈希索引 (Adaptive Hash Index) 功能。当 InnoDB 注意到某些索引值被频繁查询时,会在内存中自动基于 B+Tree 索引建立哈希索引,以加速等值寻找。
B-Tree
B-Tree:
- 点击查看演示
- B树是一种多路平衡查找树。这里的“多路”是指一个节点可以有多个子节点(不像二叉树只有 2 个)
- 以一颗最大度数(max-degree)为5(5阶)的b-tree为例(每个节点最多存储4个key,5个指针)
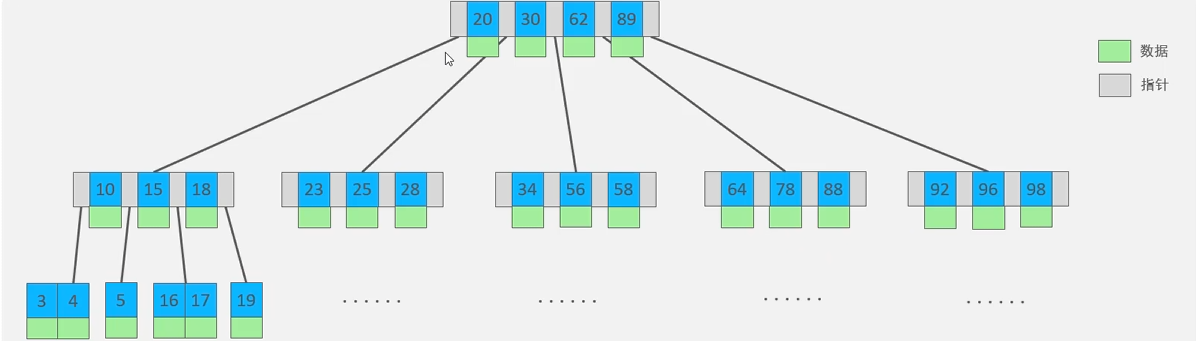
核心特征:
节点包含数据: 每个节点既存储了索引键 (Key),也存储了对应的整行数据 (Data)
自平衡: 无论插入多少数据,树的高度始终保持平衡,确保查询效率稳定在 $O(\log n)$。
搜索规则: 类似于二叉查找树。比当前节点小的走左边,大的走右边,中间的走中间分支。
B+Tree
相对于B树的区别:
- 所有的数据都会出现在叶子节点
- 叶子节点形成一个单向链表
以一颗最大度数(max-degree)为4(4阶)的B+Tree为例:
B+Tree 将所有数据记录节点按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点只存储索引(中间键)和指向下一层的指针。
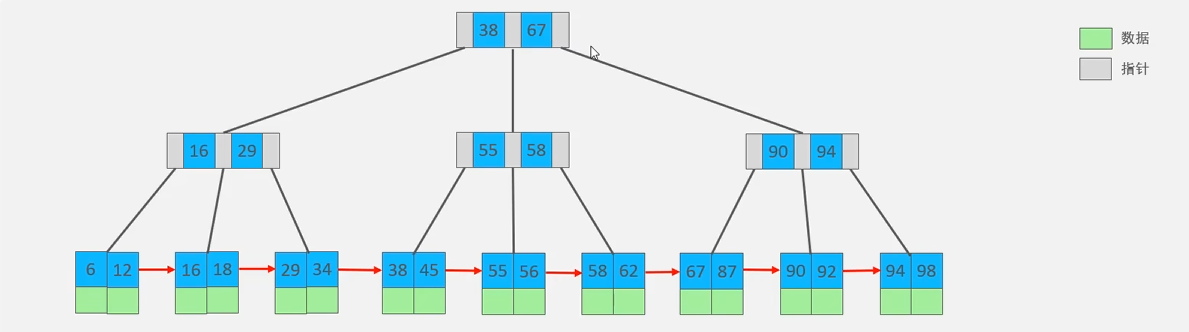
- B+Tree(B+树)是 B-Tree 的变体,也是 MySQL InnoDB 存储引擎索引的底层实现。
- 在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能 -> 利于数据库排序
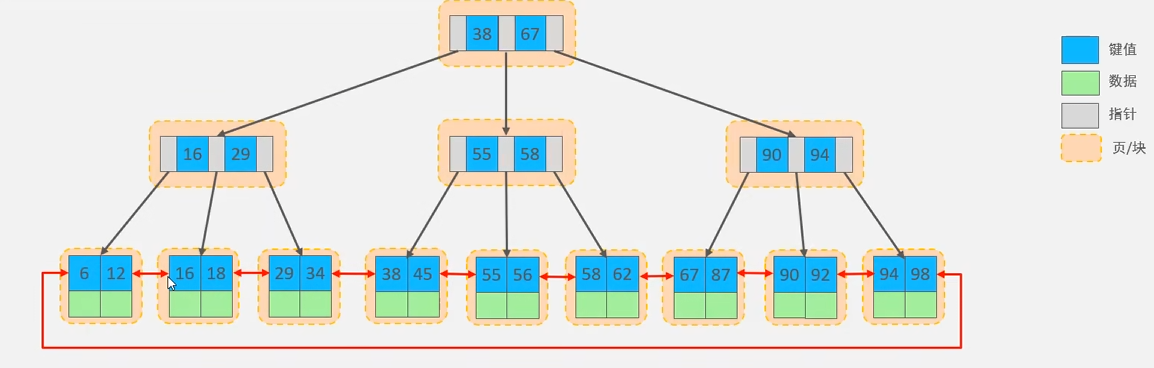
关键区别 B树:数据分布在所有节点中。适合单一 Key 查找(像 MongoDB 部分场景)。 B+树:数据仅在叶子节点中。适合范围扫描和大规模排序(MySQL 的标准选择)。
Hash索引
- 哈希索引(Hash Index)是建立在哈希表结构上的索引。
- 它通过哈希算法将列值转换为哈希码(Hash Code),并将其映射到对应的桶(Bucket)中
- 如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决
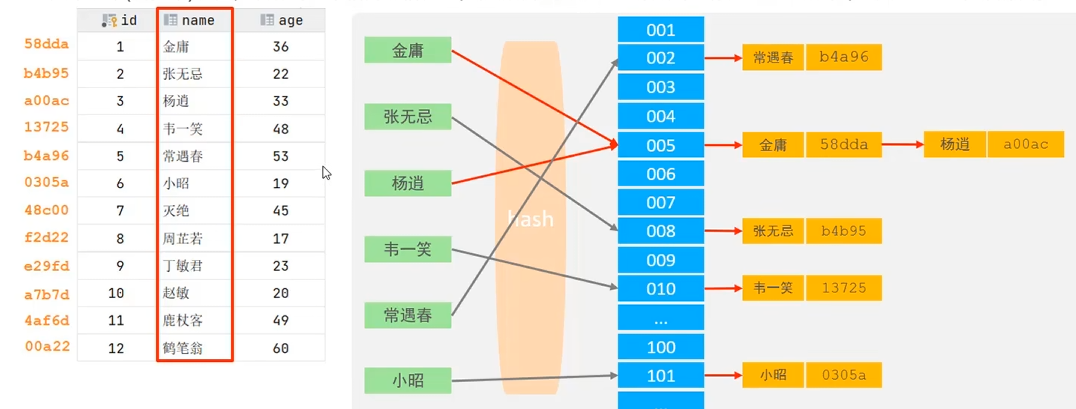
工作原理
- 计算哈希值:对索引列的每一行数据计算一个哈希码。
- 存储映射:在哈希表中存储哈希码以及指向对应数据行的指针。
- 查询匹配:查询时,对目标值计算哈希码,直接定位到对应的桶,获取行指针
Hash 索引的特点
优势:查询速度极快
等值查询:对于
=、IN、<=>操作,通常只需要一次检索即可定位数据。(前提不出现哈希冲突)复杂度:理想情况下,时间复杂度为 $O(1)$,性能优于 B+Tree 的 $O(\log n)$。
局限性(重点)
不支持范围查询:
- 哈希码的大小顺序与原始值的大小顺序无关,因此无法处理
>、<、BETWEEN或LIKE前缀匹配。
- 哈希码的大小顺序与原始值的大小顺序无关,因此无法处理
无法利用索引排序:
- 由于存储是无序的,数据库无法利用哈希索引来加速
ORDER BY操作。
- 由于存储是无序的,数据库无法利用哈希索引来加速
不支持部分索引列匹配:
- 对于复合索引,Hash 索引必须使用全部索引列才能计算哈希值。例如索引
(A, B),只查A无法使用索引。
- 对于复合索引,Hash 索引必须使用全部索引列才能计算哈希值。例如索引
哈希碰撞(Hash Collision):
- 如果大量不同键值的哈希码相同,会导致碰撞,此时需要遍历链表,查询效率会随之下降。
在MySQL中,支持hash索引的是Memory引擎,而innoDB中具有自适应hash功能,hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的
问题…
为什么InnoDB存储引擎选择使用B+tree索引结构?
虽然 Hash 索引查询单条数据是 $O(1)$,但它不支持模糊查询(
LIKE)和范围查询(><),且容易产生哈希冲突。因此 InnoDB 只将其作为“自适应哈希索引”插件使用,核心结构依然是 B+Tree对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低
相对Hash索引,B+Tree支持范围匹配及排序操作
为什么数据库初衷想用 B树?
相比于二叉树(如红黑树、AVL树),B树在数据库中有巨大优势:
降低树的高度: 数据库数据量极大。二叉树太高了,意味着找个数据要进行很多次磁盘 IO。B树通过增加“路数”,让树变得“矮胖”,通常 3-4 层就能支撑百万级数据。
磁盘预读策略: 数据库每次从磁盘读数据都是按“页(Page)”读的。B树的节点大小可以设计得刚好等于一个磁盘页,一次 IO 就能把一整个节点加载到内存。
索引分类
从逻辑业务层面分类
| 索引名称 | 关键字 | 功能描述 | 限制 |
|---|---|---|---|
| 主键索引 | PRIMARY KEY | 针对表的主键创建的索引。 | 默认自动创建,唯一且不允许 NULL。 |
| 唯一索引 | UNIQUE | 避免同一个表中某列的数据重复。 | 允许有 NULL 值,但值必须唯一。 |
| 常规索引 | INDEX / KEY | 快速定位特定数据,最常用的类型。 | 无限制,可重复。 |
| 全文索引 | FULLTEXT | 用于在大量文本中查找关键词。 | 主要用于 CHAR、VARCHAR、TEXT。 |
从物理存储层面分类 (InnoDB 引擎核心)
| 类型 | 定义 | 特点 | 选取/规则 |
|---|---|---|---|
| 聚集索引 | 数据与索引存放在一起,叶子节点存储完整行数据 | 每张表有且只有一个 | 1. 主键优先 2. 无主键则用第一个唯一索引 3. 都无则自动生成隐式 rowid |
| 二级索引 | 数据与索引分开存储,叶子节点存储主键值 | 一张表可以有多个 | 查找非索引字段需要执行回表查询 |
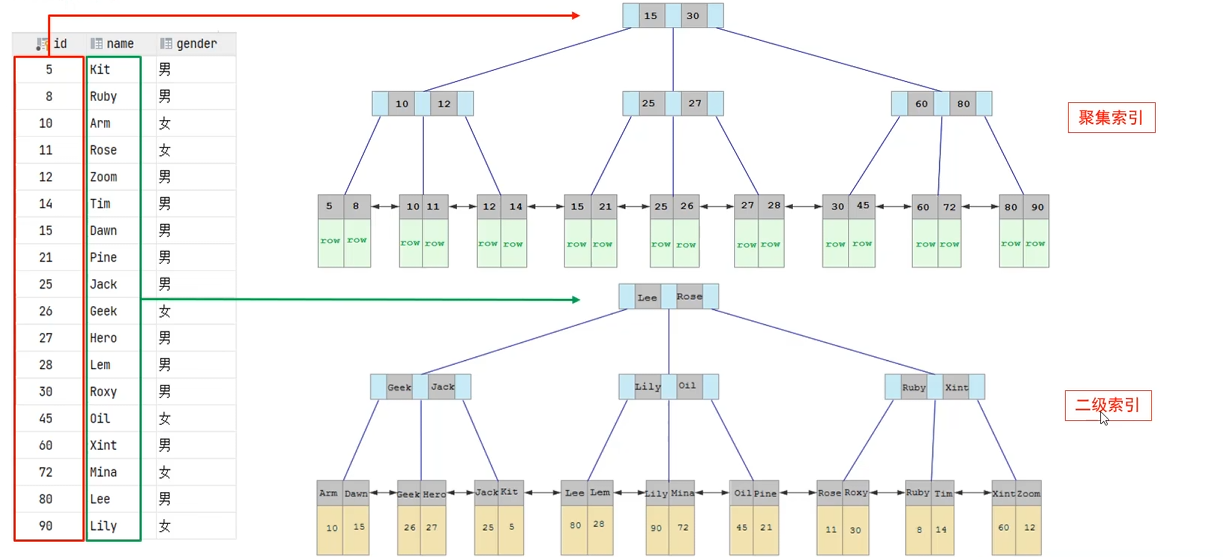 | |||
 |
问题…
为什么不建议在所有列上都建索引?
- 虽然索引能加快查询,但每增加一个索引,都会增加 INSERT/UPDATE/DELETE 的开销,因为数据库在修改数据的同时还要维护索引树的有序性。
- 同时,索引也会占用额外的物理磁盘空间
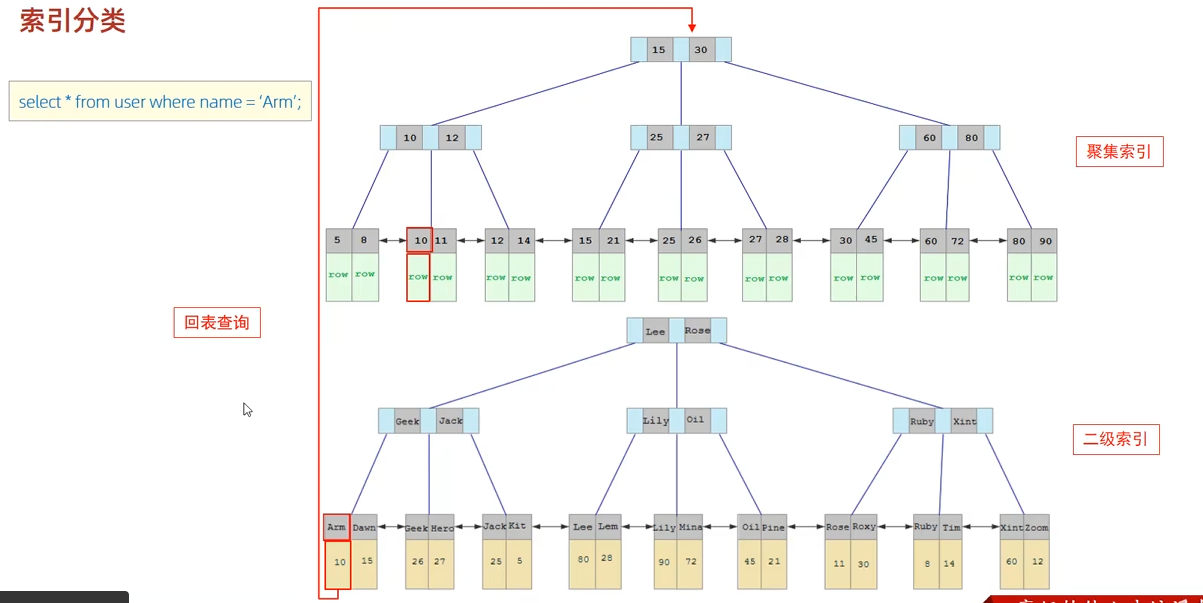
以下SQL语句,哪个执行效率高,为什么?
SELECT * FROM user WHERE id = 10;
SELECT * FROM user WHERE name = 'Arm';
-- 备注:id 为主键,name字段创建的有索引
第一条语句:基于 id(聚簇索引)
搜索路径:直接在主键 B+Tree 中搜索。
结果获取:由于主键索引是聚簇索引,它的叶子节点直接存放了这一行的完整数据。
效率:只需搜索一棵树,找到
id=10的节点后,直接取出整行记录。
第二条语句:基于 name(二级索引/辅助索引)
第一步(搜索二级索引):在
name字段的 B+Tree 中搜索'Arm'。二级索引的叶子节点存放的是该行对应的主键值(即id=10)。第二步(回表查询):拿到主键值后,程序必须再跑去主键索引树里搜一遍,才能拿到
SELECT *所需的完整行数据。效率:需要搜索两棵树。这个过程被称为 “回表”(Look-up),多了一次树的遍历和可能的磁盘 I/O。
| 步骤 | WHERE id = 10 | WHERE name = ‘Arm’ | |
|---|---|---|---|
| 第一步 | 查找主键 B+Tree | 查找 name 索引 B+Tree | |
| 第二步 | 直接返回数据 | 获取主键值 | |
| 第三步 | - | 回到主键 B+Tree 查找完整数据(回表) | |
| I/O 次数 | 较少 | 较多 |
InnoDB主键索引的B+tree高度为多高
InnoDB 的 B+Tree 高度通常在 3 到 4 层,因为根节点和二级节点存的是‘主键+指针’(16KB 的页约能存 1170 个分支),只有叶子节点存‘整行数据’(约能存 16 行),这种‘矮胖’结构使得 3 层树就能支撑约 2190 万行数据的极速查询。
索引语法
创建索引
CREATE [UNIQUE | FULLTEXT] INDEX 索引名 ON 表名 (字段名,...);
--
-- 为 user 表的 name 字段创建常规索引
CREATE INDEX idx_user_name ON tb_user(name);
-- 为 user 表的 phone 字段创建唯一索引
CREATE UNIQUE INDEX idx_user_phone ON tb_user(phone);
-- 为 user 表的 name, age, status 创建联合索引
CREATE INDEX idx_user_name_age_sta ON tb_user(name, age, status);
- 字段说明:
UNIQUE:可选,创建唯一索引FULLTEXT:可选,创建全文索引(字段名,...):如果是多个字段,则为联合索引
查看索引
SHOW INDEX FROM 表名;
-- 格式化输出
SHOW INDEX FROM 表名\G;
删除索引
DROP INDEX 索引名 ON 表名;
SQL性能分析
查看 SQL 执行频率
了解当前数据库是以查询为主,还是以增删改为主,决定了优化的侧重点。
- 命令:
-- 查看全局 session 的状态信息
SHOW GLOBAL STATUS LIKE 'Com_______';
- 说明:通过
Com_select(查询)、Com_insert(插入)、Com_update(更新)、Com_delete(删除) 的次数,可以判断数据库的负载特征。如果以查询为主,则应重点关注索引优化。
慢查询日志(Slow Query Log)
- 慢查询日志记录了 所有执行时间超过指定参数(
long_query_time,单位:秒,默认10秒)的 SQL 语句。
- 查看开关状态:
show variables like 'slow_query_log';* 开启配置(在/etc/my.cnf中):
# 开启慢查询日志
slow_query_log=1
# 设置慢查询阈值为2秒
long_query_time=2
show profiles (查看执行耗时)
show profiles能够帮助我们了解 SQL 在执行过程中,时间具体消耗在了哪个环节(如:Sending data, Sorting, Copying to tmp table)。
- 查看支持情况:
SELECT @@have_profiling; - 开启:
SET profiling = 1; - 使用步骤:
- 执行 SQL 语句。
- 查看所有 SQL 的简要耗时:
SHOW PROFILES; - 查看特定 query_id 的详细阶段耗时:
SHOW PROFILE FOR QUERY [query_id]; - 查看 CPU 消耗:
SHOW PROFILE CPU FOR QUERY [query_id];
explain 执行计划
这是最常用的性能分析手段。在 SELECT 语句前加上 EXPLAIN 关键字,MySQL 会模拟执行并返回该 SQL 的执行计划。
EXPLAIN SELECT 字段 FROM 表 WHERE 条件;
重点关注字段说明:
| 字段 | 含义 | 状态解析 |
|---|---|---|
| id | 查询序列号 | id 相同,执行顺序由上至下;id 不同,值越大优先级越高。 |
| select_type | 查询类型 | SIMPLE (简单查询), PRIMARY (主查询), UNION, SUBQUERY。 |
| type | 连接类型 | 性能由好到差:NULL>system > const > eq_ref > ref > range > index > ALL。至少达到 range 级别,要求 ref。 |
| possible_keys | 可能用到的索引 | 显示可能应用在这张表上的索引。 |
| key | 实际用到的索引 | 如果为 NULL,则没有使用索引。 |
| key_len | 索引使用的字节数 | 越短越好(不损失精确性的前提下)。 |
| rows | 扫描行数 | 预估扫描的行数,越小越好。 |
| Extra | 额外信息 | Using filesort (效率低), Using temporary (效率低), Using index (性能好)。 |
索引使用规则
最左前缀法则 (Most Left Prefix Rule)
如果索引了多列(联合索引),要遵守最左前缀法则。指的是查询从索引的最左列开始,并且不跳过索引中的列。 如果跳过,索引将部分失效
- 匹配规则:必须包含索引最左边的列。如果跳过了某列,该列及后面所有的索引失效。
- 案例:
- 建立联合索引
idx_user_pro_age_sta (profession, age, status)
- 建立联合索引
*建立索引* profession -> age -> stats
WHERE profession = '软件工程' AND age = 31 AND status = '0' (全生效)
-- 字段顺序不会影响索引
WHERE age = 31 AND status = '0' AND profession = '软件工程';(全生效)
WHERE profession = '软件工程' (生效)
WHERE age = 31 AND status = '0' (失效,跳过了最左列)
WHERE profession = '软件工程' AND status = '0'(只有 profession 生效,status 失效)
范围查询 (Range Query)
联合索引中,出现范围查询(>, <),范围查询右侧的列索引失效。
- 案例:
WHERE profession = '软件工程' AND age > 30 AND status = '0'- 此时
status字段无法用到索引。 - 规避方案:在业务允许的情况下,尽量使用
>=或<=,这样可以避免索引失效。
- 此时
索引失效场景
函数/运算操作:在索引列上进行运算或使用函数,索引失效。
- 失效:
WHERE substring(phone, 10, 2) = '15' - 失效:
WHERE age + 1 = 20
- 失效:
字符串不加引号:字符串类型字段查询时不加单引号,MySQL 会进行隐式类型转换,导致索引失效。
- 失效:
WHERE phone = 13800001111(应为'13800001111')
- 失效:
模糊查询:如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
- 有效:
WHERE name LIKE '张%' - 失效:
WHERE name LIKE '%张'或WHERE name LIKE '%张%'
- 有效:
OR 连接条件:用
OR分割开的条件,如果OR前的列有索引,而后面的列没有索引,那么涉及的索引都不会被用到。- 解决方案:对于无索引的列也建立索引
- 注意:两侧必须有各自的索引
数据分布影响:如果 MySQL 评估使用索引比全表扫描更慢(例如查询的数据占全表绝大多数),则不会使用索引
SQL 提示 (SQL Hint)
当一个字段有多个索引可选时,我们可以通过 SQL 提示来“建议”或“强制” MySQL 使用哪个索引。
- USE INDEX(建议):
SELECT * FROM tb_user USE INDEX(idx_user_name) WHERE name = '张三';
- IGNORE INDEX(忽略):
SELECT * FROM tb_user IGNORE INDEX(idx_user_name) WHERE name = '张三';
- FORCE INDEX(强制):
SELECT * FROM tb_user FORCE INDEX(idx_user_name) WHERE name = '张三';
覆盖索引 (Covering Index)
覆盖索引是性能优化的极致目标。
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到),减少SELECT*
- 原理:无需回表查询(无需回到聚集索引中找行数据)。
- 判定:在
EXPLAIN的Extra列中出现Using index。
Using index condition:查找使用了索引,但是需要回表查询数据Using where ; using index:查找使用了索引,但是需要的数据在索引列中能找到,所以不需要回表查询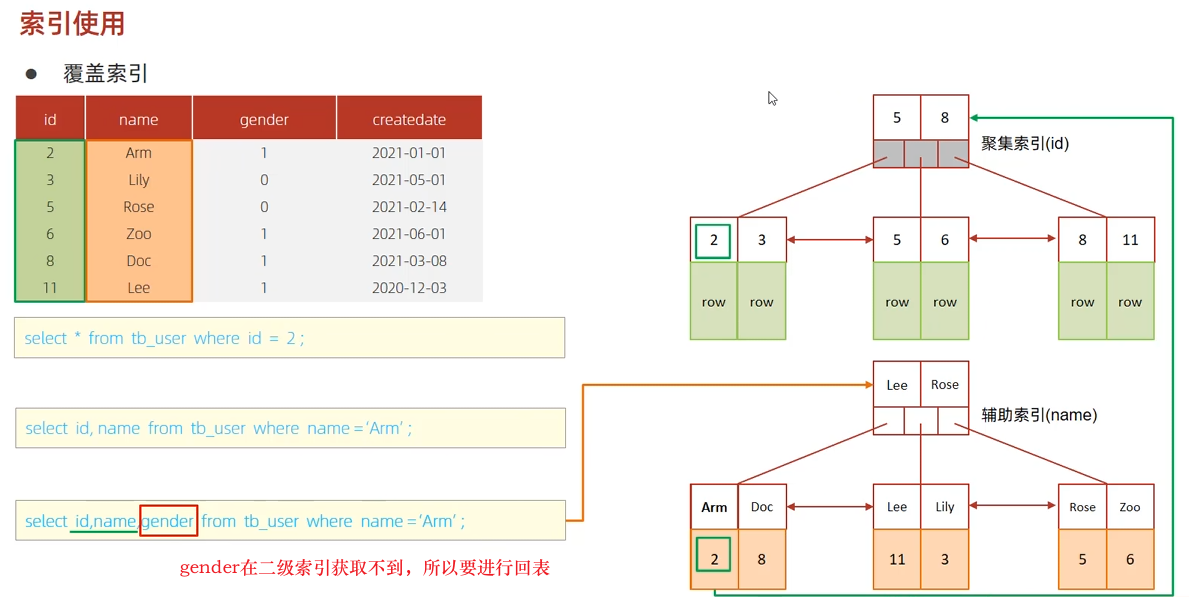
问题
- 一张表,有四个字段(id,username,password,status)由于数据量大,需要对以下SQL语句进行优化
- 该如何进行才是最优方案:
select id,username,password from tb user where username = 'itcast';
| 方案 | 索引配置 | 查询行为 | 评价 |
|---|---|---|---|
| 方案一(差) | 无索引 | 全表扫描 | 随着数据量增大,性能直线下降。 |
| 方案二(中) | INDEX(username) | 索引查找 + 回表 | 能定位,但需要回表去查 password,有额外 I/O。 |
| 方案三(优) | INDEX(username, password) | 覆盖索引扫描 | 最快。 无需回表,数据直接从索引树取出。 |
前缀索引
当字段类型为长文本(如 TEXT 或很长的 VARCHAR)时,建立完整索引会导致索引文件巨大,查询浪费大量磁盘IO,效率低。
此时可以只将字符串的前一部分建立索引,这样可以大大节约索引空间,从而提高索引效率
- 语法:
CREATE INDEX idx_xxx ON table_name(column(n)); - 选择性:前缀的长度
n取决于字段的选择性(不重复的索引值 / 总行数),选择性越高效率越高。
/*
索引选择性 = 不重复的索引值数量(基数) / 总记录数
取值范围:0 ~ 1
选择性越接近 1,索引的区分度越高,查询效率越好
唯一索引的选择性是 1,是最优情况
*/
-- 计算完整 email 字段的选择性
select count(distinct email) / count(*) from tb_user;
-- 计算 email 前 5 个字符的选择性
select count(distinct substring(email,1,5)) / count(*) from tb_user;
| 维度 | 完整列索引 (Full Index) | 前缀索引 (Prefix Index) | 影响分析 |
|---|---|---|---|
| 存储空间 | 较大(占用磁盘多) | 极小(显著节省空间) | 数据量越大,前缀索引的成本优势越明显。 |
| 写入性能 (DML) | 较慢(索引树维护重) | 较快(索引页更紧凑) | 插入和更新长字符串时,前缀索引负担更轻。 |
| 查询定位速度 | 极快(精准匹配) | 快(但存在哈希冲突风险) | 如果前缀区分度高,两者定位速度接近。 |
| 覆盖索引 | 支持 (Using index) | 不支持 (必须回表) | 前缀索引无法提供完整字段值,必须回主表二次验证。 |
| 排序 (ORDER BY) | 支持 | 不支持 | 数据库无法利用前缀的顺序来完成全字段的排序。 |
| 分组 (GROUP BY) | 支持 | 不支持 | 必须拉取完整数据到内存中进行分组计算。 |
| 区分度 (Selectivity) | 最高 | 取决于截取长度 | 截取太短会导致索引失效(类似全表扫描)。 |
单列索引与联合索引
| 维度 | 单列索引 (Single-Column Index) | 联合索引 (Composite/Joint Index) |
|---|---|---|
| 定义 | 基于表中的一个列建立的索引。 | 基于表中的两个或多个列建立的索引。 |
| B+树键值 | 节点中只包含 [该列值 | 主键ID]。 | 节点中包含 [列1, 列2, 列3... | 主键ID]。 |
| 排序规则 | 按该列的逻辑顺序排列。 | 按创建索引时的列顺序,逐级排序(字典序)。 |
- 优缺点
| 维度 | 单列索引 | 联合索引 |
|---|---|---|
| 优点 | 灵活,适用于多种不同的简单查询;索引维护成本相对低。 | 复合查询性能极强;支持覆盖索引;减少索引文件总数(相比建多个单列)。 |
| 缺点 | 在多条件复合查询下,过滤效率不如联合索引。 | 遵循最左前缀,灵活性差;索引列多时,单条记录变宽,单页存储数量下降。 |
| 适用场景 | 字段分布散、查询条件单一、或该列在多个不同场景被单独引用。 | 存在高频的多个字段组合查询;需要通过索引覆盖来规避大表回表。 |
设计原则
数据规模与查询频次
原则: 针对于数据量较大,且查询比较频繁的表建立索引。
解读: 小表或极少查询的表建立索引的意义不大,反而会增加维护开销。
关键操作字段
原则: 针对于常作为查询条件(where)、排序(order by)、**分组(group by)**操作的字段建立索引。
解读: 索引不仅能加速过滤,还能利用 B+ 树的有序性加速排序和分组过程。
选择性与区分度
原则: 尽量选择区分度高的列作为索引,尽量建立唯一索引。
解读: 区分度越高(重复值越少),MySQL 优化器使用索引的效率越高。
字符串长字段处理
原则: 如果是字符串类型的字段,且字段长度较长,可以针对字段的特点建立前缀索引。
解读: 通过截取字段的前一部分建立索引,可以节省存储空间并提升 I/O 效率。
联合索引优先
原则: 尽量使用联合索引,减少单列索引。
解读: 联合索引在很多时候可以实现覆盖索引(Covering Index),从而避免回表查询,节省存储空间并显著提高查询效率。
控制索引数量
原则: 要控制索引的数量,索引并不是多多益善。
解读: 索引越多,维护索引结构的代价(磁盘 I/O 和 CPU)也就越大,会直接影响**增删改(INSERT/DELETE/UPDATE)**的效率。
NULL 值约束
原则: 如果索引列不能存储 NULL 值,请在创建表时使用 NOT NULL 约束它。
解读: 当优化器知道每列是否包含 NULL 值时,它可以更好地确定哪个索引最有效地用于查询。此外,索引 NULL 值在存储和计算上更复杂。
 豫公网安备41019702004633号
豫公网安备41019702004633号